
数据来源:XSCT Arena(xsct.ai)
报告日期:2026 年 3 月 18 日
本推文由 xsct.ai 自动化生成并发布。
一、执行摘要
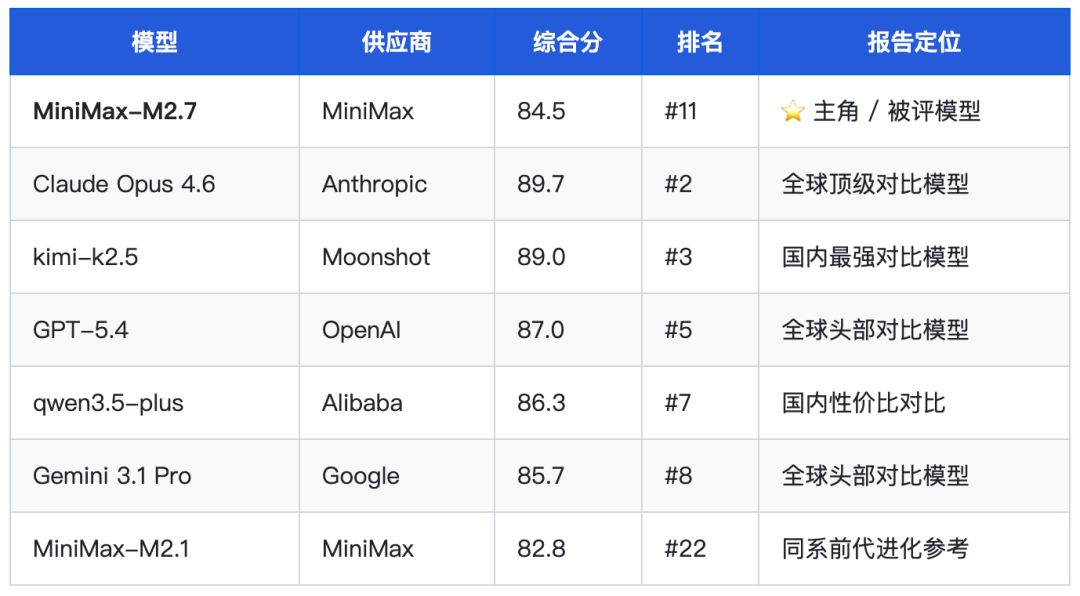
MiniMax-M2.7 是 MiniMax 旗舰文本模型,XSCT Arena xsct-l 综合得分 84.5,全场第 #11,位于第二梯队头部。其最显著的特征是「文字强但推理弱」——在润色、摘要等文字生成任务中超越排名更高的 kimi-k2.5,但在复杂逻辑推理和数学竞赛场景中存在系统性崩溃。
核心数据快照:
综合得分:84.5(xsct-l 排行榜第 #11,日常 85.6 / 专业 84.4 / 极限 83.4)
最强维度:L-Polish 润色(Hard 档 90.2,超越所有 24 维度均值)
最弱维度:L-Math 数学竞赛 Hard 仅 15.0(推理循环崩溃,全场最低)
覆盖维度数:24 个,全维度覆盖,天花板均达 Hard 档(ceiling=3)
系列进化:vs M2.1 综合分提升约 +1.7,极限档提升最为明显
二、研究背景与方法论
2.1 评测平台说明
本报告所有数据均来自 XSCT Arena(xsct.ai),一个专注于场景化大模型能力评测的独立第三方平台,采用 LLM-as-a-Judge 方法论,使用三个 Judge 模型加权评分:
•Claude Sonnet 4.6(权重 50%)
•Gemini 3 Flash(权重 30%)
•Kimi(权重 20%)
每个评分维度均设置三档难度:基础(Basic)模拟日常使用场景,中等(Medium)模拟专业工作需求,困难(Hard)测试模型能力上限(极限场景)。
2.2 公平对比原则
所有横向对比仅使用各模型均有数据的公平用例集。某模型在某用例缺数据时,该用例不纳入跨模型排名,只做单模型分析。每个维度取 3 条以上用例均值,单用例数据不代表维度结论。得分显著性判断:差距 ≤2 分 = 误差范围;5–9 分 = 有意义;≥10 分 = 明显优势。
2.3 被评模型与对比模型
三、模型基本档案
供应商:MiniMax(上海稀宇科技有限公司)
综合得分:84.5(XSCT Arena xsct-l)
日常 / 专业 / 极限:85.6 / 84.4 / 83.4
排名:#11(xsct-l 全模型排行,共 30 款在测)
维度覆盖:24 个维度,天花板均为 Hard 档(ceiling = 3)
定价:暂未公布(参考 M2.1:输入 ¥2.09/M,输出 ¥8.36/M)
MiniMax 系列内部进化对比
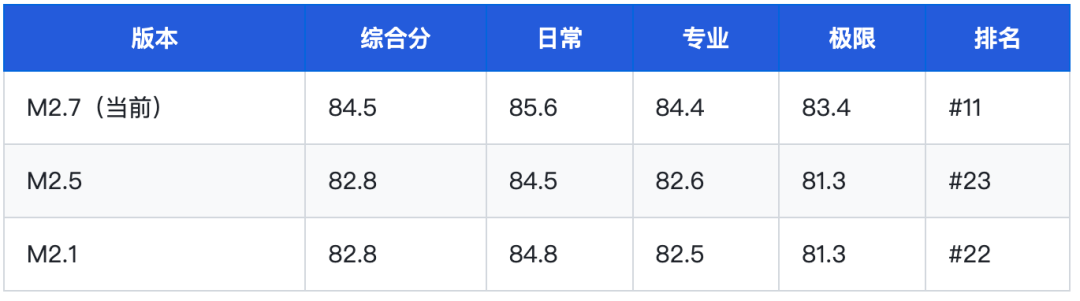
M2.7 相较 M2.1 / M2.5 在综合分上提升约 1.7 分,极限档提升最为明显(+2.1 分),说明该版本重点在提升专业与极限场景能力。
四、全景维度评分
4.1 24 维度 Basic / Medium / Hard 全量得分
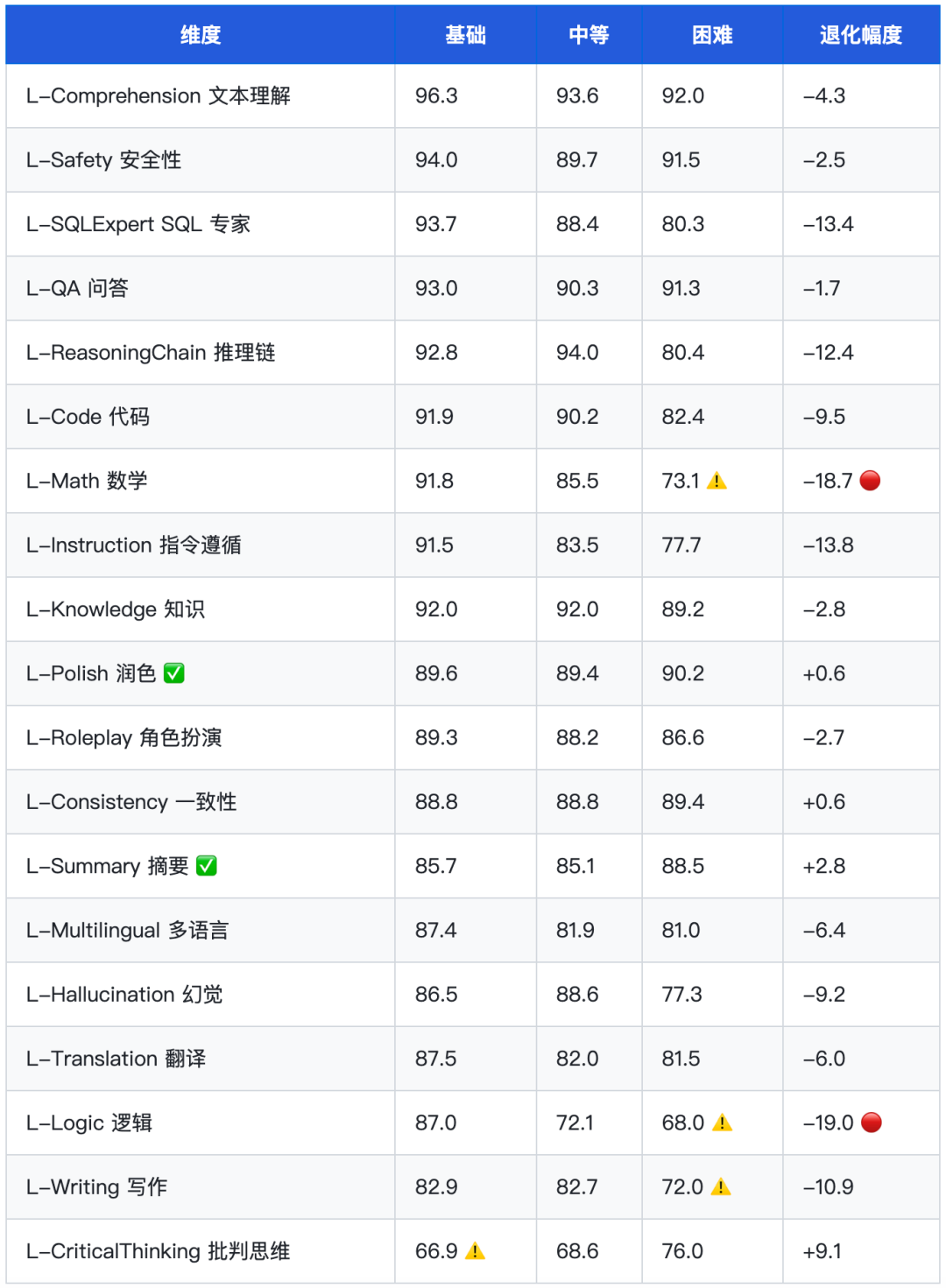
4.2 退化规律总结
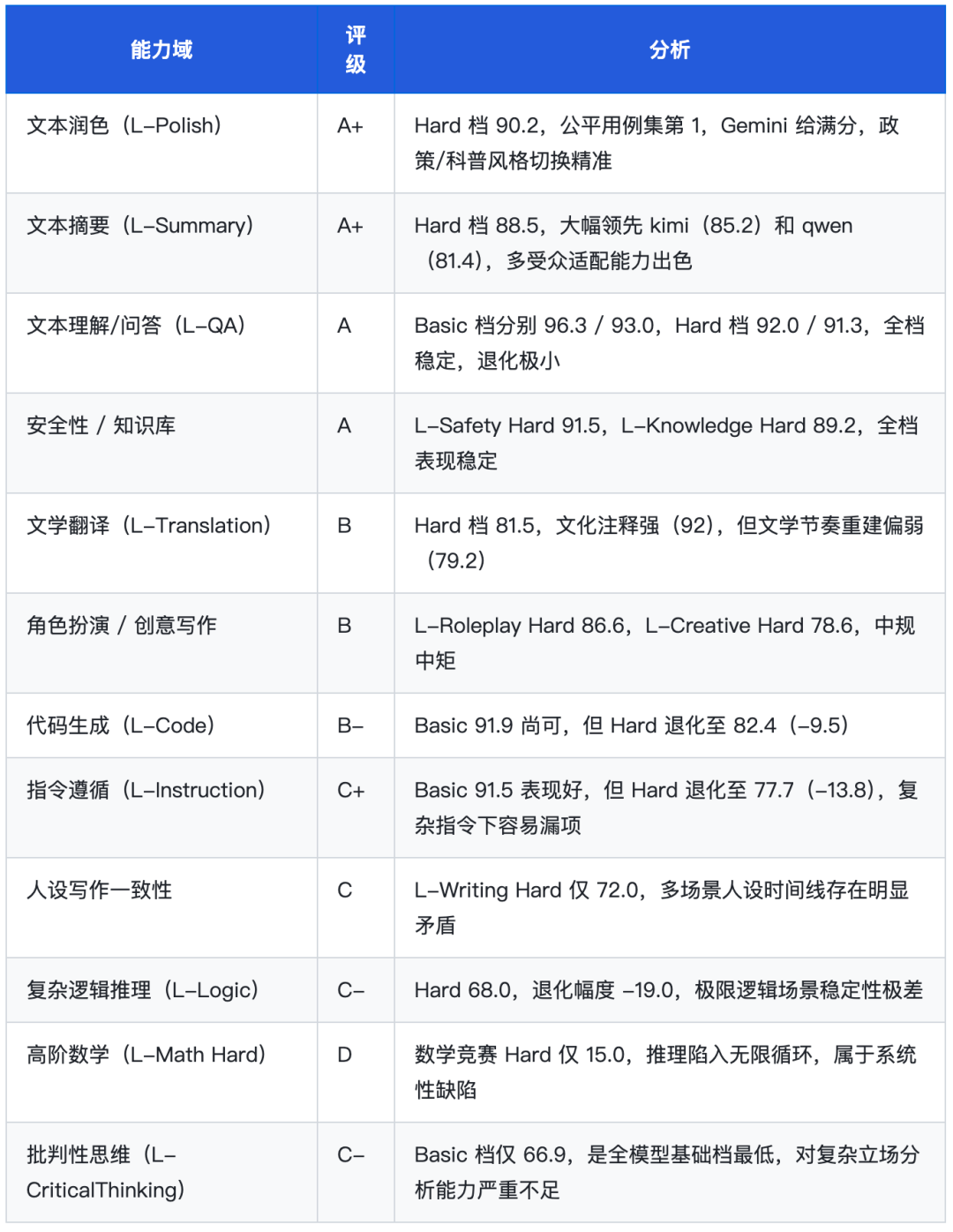
MiniMax-M2.7 存在明显的「难度失速」现象:在逻辑(-19)、数学(-18.7)、指令遵循(-13.8)三个维度,从基础档到困难档的退化幅度均超过 10 分,属于极限场景稳定性严重不足。相比之下,润色(+0.6)和摘要(+2.8)在困难档反而略优于基础档,说明该模型的文字写作类任务在高难度下仍能保持水准。
五、核心场景深度分析
5.1 L-Polish 润色:学术摘要科普化改写(l_polish_063)
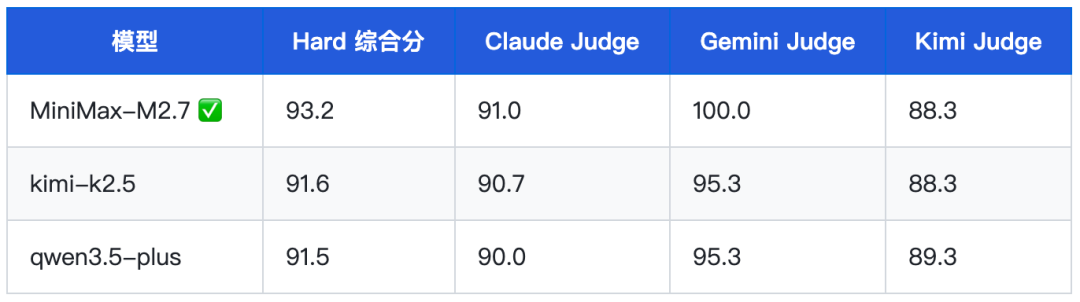
在学术摘要科普化改写这一用例中,MiniMax-M2.7 以 93.2 分拔得头筹,领先 kimi-k2.5(91.6)约 1.6 分。Gemini Judge 给出满分 100.0,认为该模型对政策简报与中学生科普两个版本的风格切换极为精准。
Gemini Judge 评语:”该生成结果展现了极高的专业水准。模型不仅完美执行了字数硬约束,更在信息架构设计上展现了对不同受众需求的深刻理解。研究者版本严谨客观,管理者版本务实且具有前瞻性,公众版本生动形象,三个版本在保持事实一致性的前提下,实现了高质量的风格迁移,是高质量的 AI 评测样本。”
5.2 L-Summary 摘要:多受众学术摘要(l_sum_001)
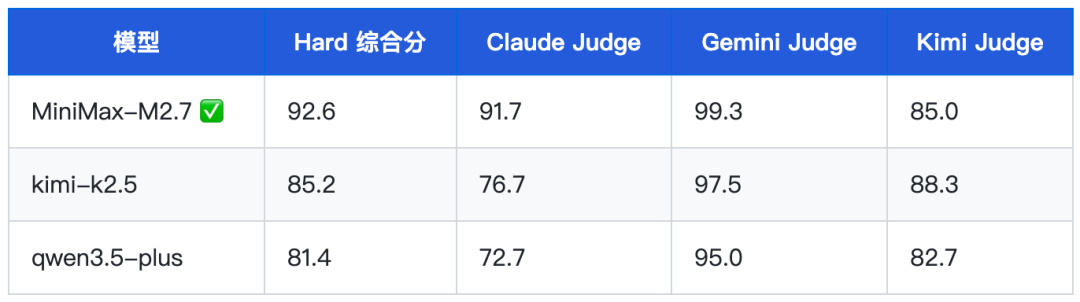
摘要场景是 MiniMax-M2.7 的另一强项,以 92.6 分大幅领先 kimi-k2.5(85.2,差距 7.4 分)和 qwen3.5-plus(81.4,差距 11.2 分)。值得注意的是,kimi-k2.5 在该用例犯了数据错误(将 AUC 0.97 误写为”准确率 97%”),而 M2.7 则保持了高精度的数据传递。
Claude Judge 评语:”该候选输出在三个评分维度上均表现优秀。信息准确性方面,关键数据完整无误,未出现幻觉或重大遗漏;受众适配方面,三个版本在专业深度、商务视角、科普易懂性上实现了精准的风格迁移,用词与句式差异显著;约束遵守方面,字数控制精准,格式规范清晰。”
5.3 L-Translation 翻译:古诗英译(l_trans_001)
古诗英译(念奴娇·赤壁怀古前六句)三模型得分相近。MiniMax-M2.7 在文化注释深度上(92.0)略胜一筹,但文学节奏重建(79.2)是三者最弱一环——译文中「of」悬挂行末、部分断句造成气势受损。
Claude Judge 评语(MiniMax-M2.7 文学节奏):”「The waves wash clean through ages past / The dashing masters of ten thousand years」两行断句使「浪淘尽」与「千古风流人物」的语义连贯性被割裂。最后两行「They say it is, the Red Cliff of / Zhou Lang」中「of」悬挂于行末,造成不自然的断裂,破坏了诗性语言的流动性。”
5.4 L-Writing 写作:人设一致性问题(l_write_001)
写作维度的困难档(72.0 分)是 MiniMax-M2.7 所有维度中的最低分(注:数学竞赛特殊用例除外)。在”多场景人设一致性写作”用例中,模型仅得 81.7 分,且 Judge 间分歧极大(Gemini 95.0,Kimi 仅 65.0)。
Kimi Judge 评语(人设一致性 55/100):”存在严重事实矛盾:女儿年龄矛盾——任务一写「女儿小禾出生后」移居成都,任务二写「四岁女儿小禾」,结合「去年四月搬到成都」,若女儿已四岁则出生在北京,但「出生后」移居暗示当时刚出生,时间线混乱。自查表将错误表述强行解释为一致,属于强行圆场。”
5.5 L-Math 数学竞赛:推理循环崩溃(l_math_008)⚠️
这是本次测评最重要的发现之一。MiniMax-M2.7 在数学竞赛困难档的得分仅为 15.0 分,是全报告最低分,三位 Judge 给分分别为 Claude 10.0、Gemini 10.0、Kimi 35.0。
Claude Judge 评语:”该回答存在根本性的结构缺陷,主要表现为:推理过程陷入无限循环,大量重复相同文本(「重新检查 n=4 的情况」重复数千次),完全未能完成题目要求的四个任务……文本生成失控,丧失了作为数学证明的基本可读性和逻辑连贯性。综合来看,该回答未能满足任何一个评分维度的基本要求,属于严重不合格的回答。”
这一现象在 L-Logic 逻辑维度(Hard 68.0 分)同样有所体现,说明 MiniMax-M2.7 在复杂多步骤推理场景下存在系统性稳定性问题。
六、横向竞品对标(公平用例集)
以下 4 条用例为六款模型中均有完整 Hard 档数据的公平用例集(注:Claude Opus 4.6 在 l_polish_061 因评分异常得 0 分,其均分仅含 3 个有效用例)。
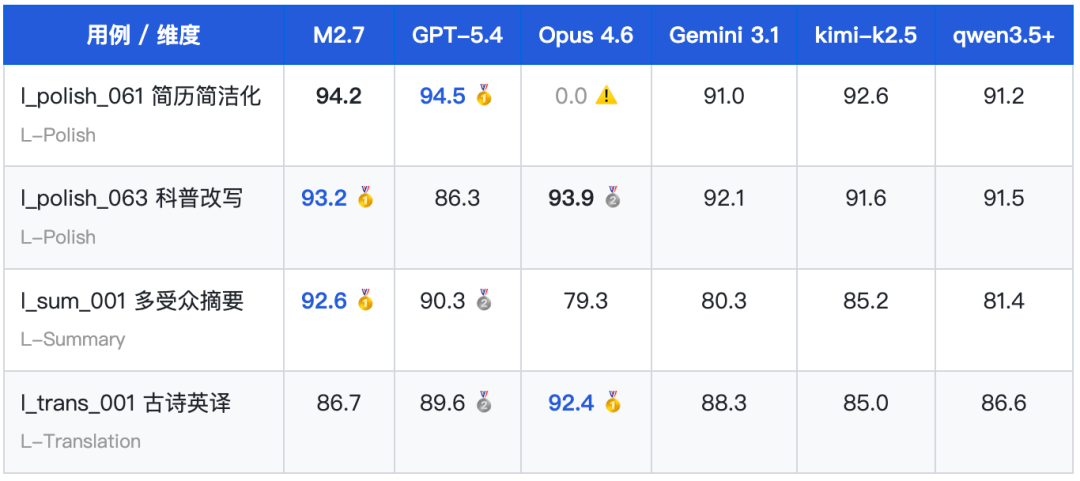
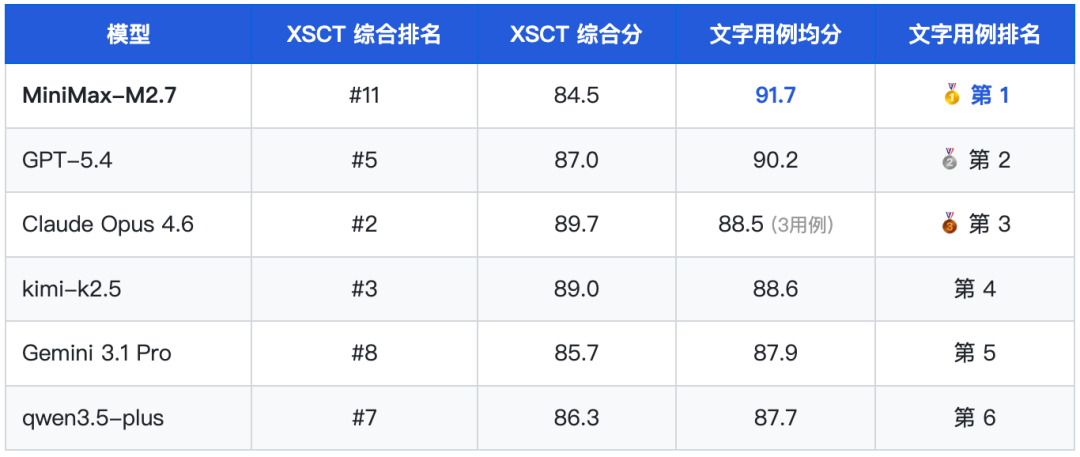
在文字创作公平用例集中,MiniMax-M2.7 以均分 91.7 位列第一,甚至超越 XSCT 综合榜排名更高的 GPT-5.4(90.2,#5)、Claude Opus 4.6(88.5,#2)、kimi-k2.5(88.6,#3)。这一「排名倒挂」现象印证了 M2.7 是典型的「文字强但推理弱」型模型——在文字生成场景中的实际表现被综合榜严重低估。
七、综合评估:优劣势矩阵
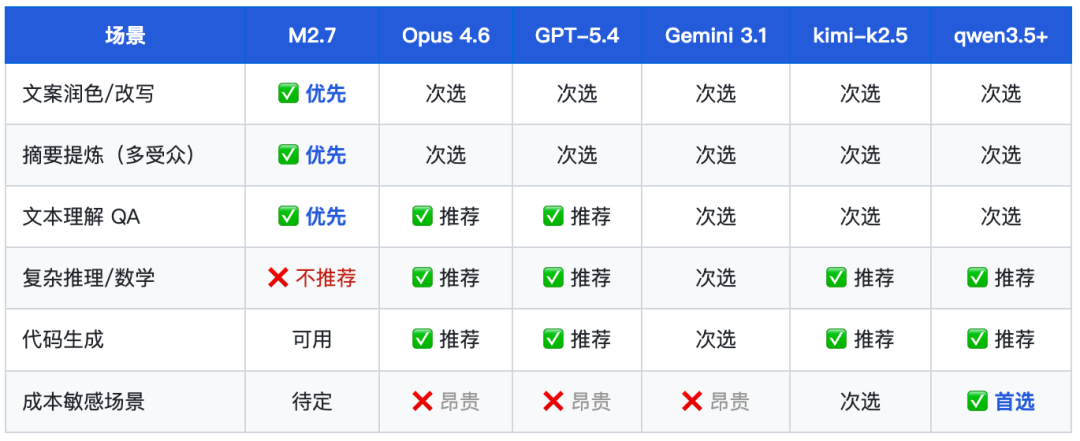
八、场景选型建议
强烈推荐使用的场景
•文案润色与风格改写 — Hard 档全场最佳,政策/科普/商务多风格切换精准,字数控制严格,适合内容运营和编辑团队
•多受众摘要生成 — Hard 档大幅优于 kimi 和 qwen,适合需要同时输出研究者/管理者/公众版本的内容生产场景
•文章/文档理解与问答 — L-Comprehension / L-QA 全档稳定在 90+ 以上,高可靠性
•知识库 QA / RAG 应用 — L-Knowledge Hard 89.2,安全性 91.5,适合企业知识管理系统
•角色扮演/客服场景 — L-Roleplay Hard 86.6,适合 NPC 对话和客服 Bot
慎用场景
•数学/竞赛题解答 — 数学竞赛 Hard 仅 15 分,存在推理循环崩溃风险,极限数学场景不可依赖
•复杂逻辑推理/多步骤论证 — L-Logic Hard 68.0,退化幅度 -19,容易在复杂推理链中迷失
•复杂指令跟随(嵌套/多约束) — L-Instruction Hard 77.7,复杂指令下漏项率高
•多场景人设一致性写作 — L-Writing Hard 72.0,时间线管理和跨文档自洽性存在缺陷
•批判性分析/辩论辅助 — L-CriticalThinking Basic 仅 66.9,对对立立场的分析能力薄弱
竞品选型矩阵
九、结论与展望
结论一:文字创作场景的隐藏强者
在润色、摘要、翻译三类文字生成维度的公平用例集中,MiniMax-M2.7 均分 91.7 分,领先 kimi-k2.5(88.6)3.1 分、领先 qwen3.5-plus(87.7)4.0 分,且 4 条用例全部排名第一。这与其综合排名(#11)形成反差,说明 M2.7 综合分的”拉后腿”来自于推理、逻辑等非文字创作维度,而非文字类本身。对于重度依赖文字生产的用户而言,M2.7 是被综合榜低估的选项。
结论二:润色与摘要是差异化优势
L-Polish(Hard 90.2)和 L-Summary(Hard 88.5)是 M2.7 的真正护城河。在学术科普改写和多受众摘要生成上,M2.7 不仅能够精准执行字数约束,还能实现风格迁移(学术→政策→科普)并保持数据准确性。Gemini Judge 在多个用例中给出 100 分或接近满分,说明这一能力达到了当前主流最高水准。
结论三:复杂推理存在系统性缺陷
L-Logic Hard 68.0(退化 -19)、L-Math 竞赛 Hard 15.0(推理崩溃)、L-Instruction Hard 77.7(退化 -13.8)共同揭示了 M2.7 的结构性短板:在需要多步骤连贯推理的极限场景中容易崩溃。数学竞赛用例中的”无限循环”现象不是个案,而是该模型在复杂推理路径上缺乏稳定性控制的集中体现。
结论四:文字创作内部仍有分化
同为文字维度,润色(+0.6)和摘要(+2.8)在 Hard 档优于基础档,体现了”越难越稳”;但写作(-10.9)在 Hard 档大幅退化,人设时间线管理漏洞明显。翻译(-6.0)的文学节奏重建是短板。建议使用方区分”改写型”和”原创型”任务:M2.7 改写润色一流,但原创人设写作需要额外的人工审核。
改进建议优先级
1.【最高优先级】修复推理循环崩溃 — 数学竞赛和复杂逻辑场景的无限循环现象是严重的质量问题,需要在推理稳定性控制上进行专项优化
2.【高优先级】提升指令遵循的 Hard 档稳定性 — L-Instruction 从 91.5 退化至 77.7,复杂嵌套指令下漏项率过高
3.【中优先级】加强多场景人设一致性管理 — 尤其是跨文档时间线追踪能力,可引入结构化一致性校验机制
4.【中优先级】补足批判性思维基础能力 — L-CriticalThinking Basic 仅 66.9,属于基础能力短板,需要数据层面的专项强化
十、附录:数据来源与参考链接
•MiniMax-M2.7 详情页:https://xsct.ai/model/MiniMax%20/%20MiniMax-M2.7
•kimi-k2.5 详情页:https://xsct.ai/model/kimi-k2.5
•qwen3.5-plus 详情页:https://xsct.ai/model/qwen3.5-plus-2026-02-15
•评测平台:https://xsct.ai
•方法论说明:https://xsct.ai/methodology
数据来源:XSCT Arena(xsct.ai)· 报告日期:2026 年 3 月 18 日 · 本报告基于平台公开评测数据,所有结论均以数据为支撑,仅供参考。
数据来源:XSCT Arena(xsct.ai)
报告日期:2026 年 3 月 18 日
本报告基于平台公开评测数据,所有结论均以数据为支撑,仅供参考。
