文章核心摘要: 本文是一篇详细的、关于AI Agent中Skills(技能)概念的解读和应用指南,其核心论点源自Claude Code团队工程师Thariq的文章,并结合了作者“叶小钗”的系统性思考。核心观点是:Skill的本质不是更长的提示词,而是一种可工程化、可治理的、承载组织工作流的新型工程单元。它是Agent能力的核心,是介于模型能力和工具(Tools)之间,用于沉淀和迁移流程(Workflow/SOP)的封装。以下是文章的主要内容总结,按逻辑结构梳理:1. 定义与核心理念
description是关键,它不是产品简介,而是触发协议,需清晰定义技能的解决任务、适用语言、边界与排除场景。
.claude/skills)到插件/Marketplace,再到企业统一目录,需建立准入门槛,控制上下文成本。
我之前说过,对于 Agent 来说,记忆系统/上下文工程会是一个难点/卡点,而 Skills 生态却是其真正的核心,这一点从 OpenClaw 的调教就可以看出来:
大家折腾小龙虾的时候,几乎不会关注上下文,但一定会不停打磨Skills。原因也很简单:记忆系统是黑盒、Skills 是 Workflow 的迁移
于是乎,我们很有必要再把 Skills 牵出来重新认识认识,只不过这次上更“权威”的解读:由 Claude Code 团队工程师 Thariq 撰写的长文:
Lessons from Building Claude Code:
How We Use Skills
Skills
首先,现在 Skills 的含义是很丰富的,他不是一个简单的提示词文件,而是一份能力包,并且这个能力包是可维护、可复用、可度量的。
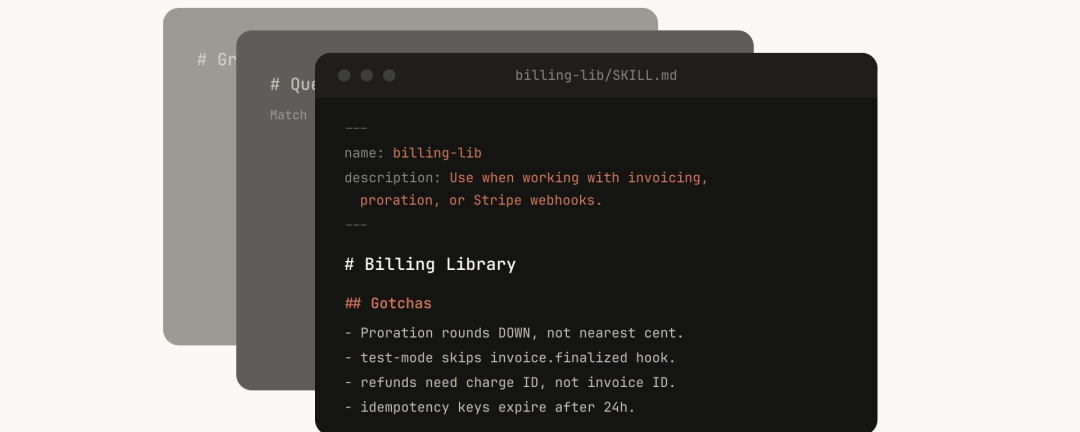
作者强调,Skill 是一个文件夹,它可携带脚本、资产、参考文档、配置、数据与 Hook;
并通过渐进式披露在不爆炸上下文的前提下,把流程沉淀为可触发的工作流,要注意这里的流程可以是个人流程也可以是组织(团队)流程。
Thariq 这篇文章的核心价值并不是其中的几段指令模板,而是他给了一个建议,这个建议的结果是一套可规模化的系统诞生了:
技能分类法(9 类):帮助你像管理产品功能一样管理技能组合; 设计原则:不要写常识、把失败点写成 Gotchas、用文件系统做渐进披露、避免过度“牵引”模型、把 setup 做成可恢复状态,把“提示工程”转为“上下文工程”; 分发与治理:从 repo 内 .claude/skills 到插件/Marketplace;从“自发试用”到“被动发现+准入门槛”,解决规模化后的冗余、冲突与上下文成本; 度量闭环:用 PreToolUse Hook 记录 Skill 调用,识别热门/低触发/过触发,把“感觉很好用”变成可迭代的增长系统。
原文链接:
https://x.com/trq212/article/2033949937936085378
不要挣扎了,我知道各位读不懂,这几个点相当于整个文章的概述,我们后面会一一解释,所以不必担心…
这里衍生两句,虽然 Skills 概念首先是 Claude 提出,但现在几乎所有基座模型都对其进行了支持,这里就是个非常清晰的趋势了: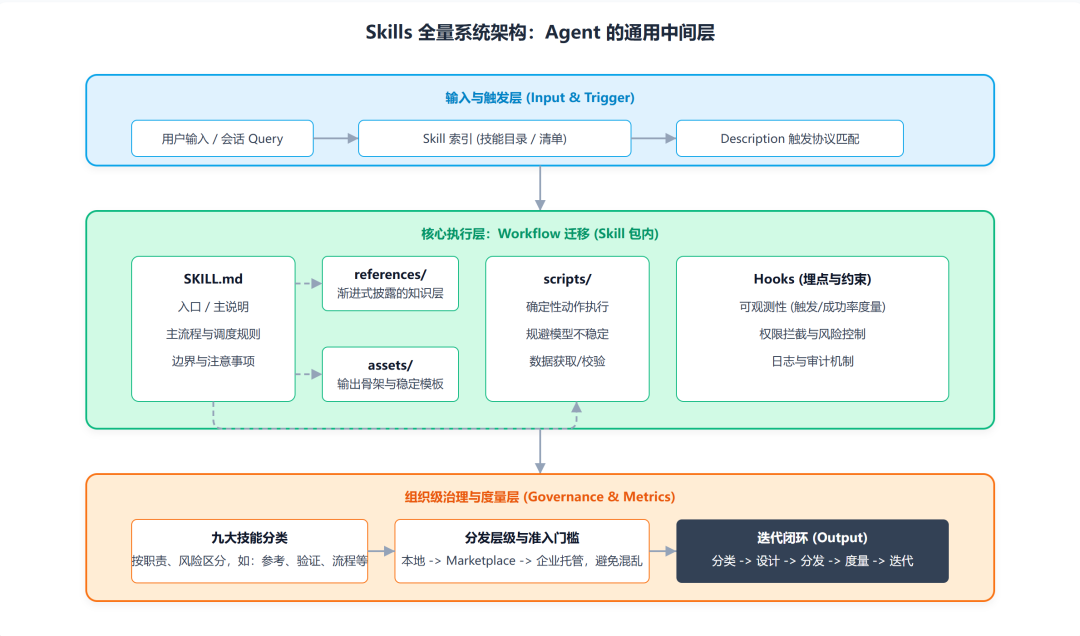
Skills 正在成为 AI Agent 的通用中间层,介于模型能力与工具(Tools)之间,用来承载流程/Workflow
Skill 说白了,就是给 Agent 用的 SOP 包。它内容的核心,很多时候也确实是 SOP…
接下来,我们做进一步拆解,说说 Skill 包的组成与运行机制:
技术解构

Skills 包/文件夹 是一种可执行的配置与资产封装格式,他的结构是这样的:
<skill-name>/
├── SKILL.md
├── references/
├── assets/
├── scripts/
└── 其他配置/数据文件
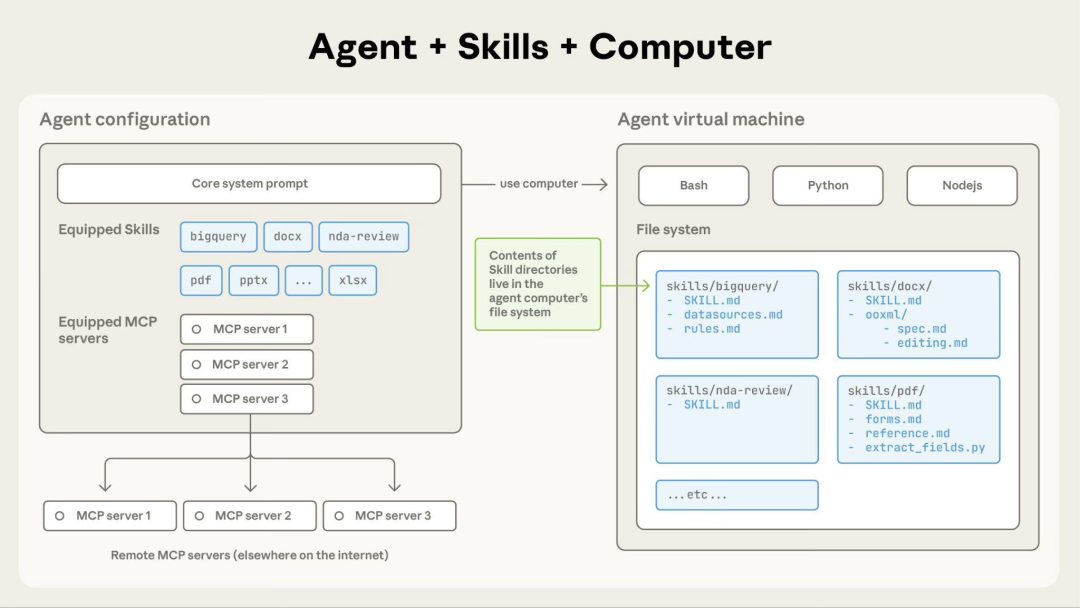
也就是说,Skill 是一个目录级能力单元:
一个 SKILL.md,作为入口与主说明 一组 references/,承载长文档、参考资料、规则解释 一组 assets/,承载模板、样例、静态资源 一组 scripts/,承载可执行脚本 以及必要时的 hooks / config / data,承载约束、配置与持久状态
我这里再强调下:Skill 的本质不是提示词增强,而是工作流的封装。
先说最外层的 SKILL.md。
一、SKILL.md:总入口
很多人会本能地认为这就是写给模型看的正文,所以总想把所有说明、所有注意事项、所有流程一步到位地塞进去。
这是第一层误解。
SKILL.md 真正扮演的角色,是这个能力包的索引页 + 路由页 + 使用说明页。它至少承担四个职责:
告诉模型这个 Skill 是干什么的 告诉模型什么情况下该触发它 告诉模型触发后先读什么、后读什么 告诉模型输出大概要长成什么样
所以 SKILL.md 是一个调度入口:
一个 Skill 包就像一个项目文件夹,SKILL.md 是这个文件夹的 README + runbook + routing contract
因为 SKILL.md 承担的是“具体怎么做”的作用,所以其写法就出来了:
主流程清晰 触发边界清晰 关键易错点明确 引导模型去按需读取其他内容
二、description:触发协议
很多 Skill 写废,不是废在内容,而是废在 description。大多数人写 description 时,写出来的东西都很像产品简介:
用于帮助分析数据 用于自动生成报告 用于产品验证 用于故障排查
这种写法对于人类读者还行,但对于模型来说,几乎是废的。因为 description 不是给人看的,它首先是给模型看的。
它在 Skill 系统中的角色,本质上是一个触发协议。也就是说,这里真正要解决的问题不是“我是谁”,而是:什么场景下,你应该想到我。
一个好的 description,至少要同时回答四件事:
我解决什么任务 这个任务通常会以什么语言被表达 哪些情况属于我的边界 哪些情况不属于我的边界
举个例子。如果你只写:
用于产品验证
那这几乎没有价值。因为“产品验证”可以是:页面验收、埋点校验、视觉对比……
这里正确的写法是:
用于 Web 产品上线前验证,适合检查主路径、核心按钮、关键埋点、错误日志和截图对比;
在需求开发完成、准备提测或上线前触发;
不用于需求评审阶段,也不用于纯文档任务
到这里大家就更清楚了,description 负责触发路由,SKILL.md 负责路由命中后的执行展开。
三、references/:知识层
前面我们说过,Skill 是 Workflow 的迁移,references 是知识层。这一层装的,不是“马上要执行的步骤”,而是:
API 文档 业务规则解释 字段口径说明 历史案例 反常识规则 系统背景知识 …
它存在的意义非常明确:
把重知识、低频读取、但关键时刻很重要的内容,从主流程里拆出去
这就是所谓的渐进式披露…
这是一个可能的目录:
references/
├── checklist-explained.md # 每个检查项为什么存在
├── common-failures.md # 历史常见翻车案例
├── screenshot-examples.md # 截图对比的正反例
└── analytics-gotchas.md # 埋点和日志的易错点
四、assets/:模板层
模型是具有一定自由度的,很多任务真正难的,不是模型不会做,而是它每次都做得不一样。比如你让它输出一份:故障复盘/周报/竞品分析……
它当然能写,但问题是格式经常出问题,assets 的作用,就是把这种“会做但不稳定”的问题,变成“有模板可依”的稳定结果:
输出骨架
固定模板
示例文件
标准结构
复用样例
一个成熟 Skill,通常不是只告诉模型“怎么做”/Workflow,还会告诉它“最后该交什么”/assets。
五、scripts/:确定性脚本
曾经 Agent 领域有一句话:More context, less control。但后续实际的演进其实是沿着关键任务 Workflow这个方向走的。
到了scripts这里,已经不只是告诉模型怎么做,而是开始把确定性动作下沉成脚本了。
如前所述,这一步的意义非常大。为什么?因为模型最擅长的是:
理解任务 做判断 做规划 做解释 串联步骤
但模型最不擅长的,其实恰恰是:
重复执行 精确校验 机械转换 固定格式输出 稳定抓取数据
这些动作,如果你让模型硬扛,最后一定会有大量不稳定。Skill 的核心设计原则就是:
能下沉成脚本的,不要继续让模型用语言硬做
其实从这里就可以看出,理念已经和之前less control有了很大的不同
具体来说,这些事就非常适合放进 scripts:
读日志并过滤错误级别 跑 SQL 并转成固定表格 调多个 API 聚合结果 校验文件结构 做页面截图与对比 执行上线前检查 生成固定格式报告 …
一步一做,Skill 的性质就变了。它只是一个教模型做事的说明书,而是开始变成一个:模型负责调度,人类经验负责约束,脚本负责执行的复合能力包。
也就是从这里开始,Skills 和 Workflow 的关系才真正显现出来。因为很多传统 Workflow 节点,本质上就是:
读取某个输入 调一个脚本 产出一个中间结果
而现在,这种节点级能力,正被重新迁移进 Skill 目录里。所以我前面说:
Skills 是 Workflow 的迁移
原本写死在工作流引擎里的那些步骤,正在以更灵活的方式,被迁移成 Agent 可调用的能力包
1. 先确认本次验证的页面范围
2. 运行 scripts/check.sh 做基础检查
3. 如果检查失败,先汇总失败项,不要直接判断通过
4. 如果检查通过,再继续做截图、埋点和日志层面的验证
5. 最后按模板输出验证报告
六、Hook:埋点
scripts 解决的是怎么稳定执行,那 Hook 解决的就是另外两个问题:
怎么加约束 怎么做埋点
这一层对组织级落地极其关键。因为个人写 Skill,最关心的是好不好用。但组织里上 Skill,关心的一定是:
会不会误用 会不会越权 会不会留下日志 会不会有副作用 会不会影响别的流程
这时候,Hook 的意义就出来了。它让你可以在 Skill 执行链路的关键位置插入确定性逻辑。
比如:
调工具前检查参数 执行危险命令前先拦截 结果生成后自动验格式 某个 Skill 被调用时自动打日志 运行结束后自动记录成功/失败
也就是说,Hook 让 Skill 具备:可观测性 + 可治理性 + 风险控制。
到了这一步,你会发现 Skill 的系统性就完全展开了。你可以把它理解成:
SKILL.md 负责讲方法 references/ 负责补知识 assets/ 负责定模板 scripts/ 负责做动作 hooks 负责加约束和埋点
这几层加起来,就是一个完整是 Skill。
然后,我们说完结构,再说运行。
运行机制
很多人养不好小龙虾,是因为不了解 SKills 的机制,要了解他除了基本的目录认识,还得清楚它到底怎么被触发、怎么被展开、怎么被执行。
其实 Skills 的逻辑是很清晰的。
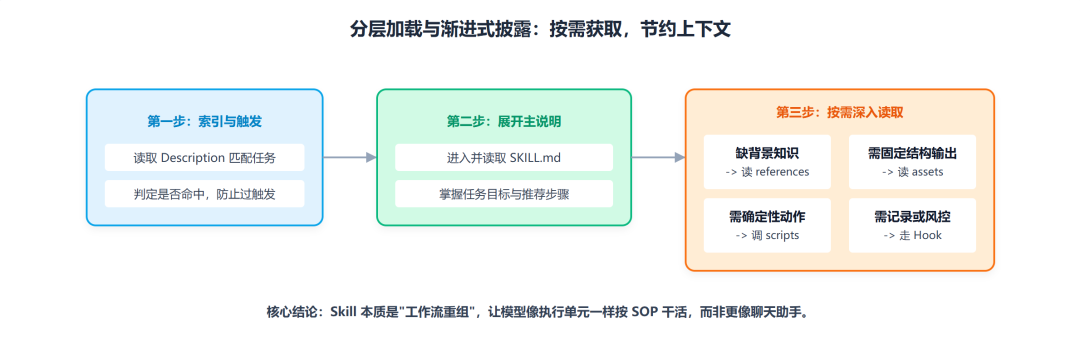
第一步:索引
一个 Skill 并不是在会话一开始就把全部内容塞进上下文。正常情况下,模型先看到的只是一个很轻量的索引层,大概包括:
Skill 名称 description,最核心 少量元信息
然后模型根据当前任务,判断有没有必要调用某个 Skill。也就是说,Skill 的第一步不是“执行”,而是“被发现”。
所以 Skill 系统本质上一定先有一层:技能目录 / 技能清单 / 技能索引。
这一层越清晰,后面的自动触发就越准;这一层越混乱,后面就越容易过触发和欠触发。
所以很多团队后面会发现,Skill 体系的第一个治理重点,不是脚本,不是模板,而是:
索引体系是否清晰,也就是 description 写得怎么样
第二步:展开
当某个 Skill 被判断命中后,模型才开始真正读取 SKILL.md。这里它拿到的是主流程说明:
任务目标 推荐步骤 使用边界 输出要求 哪些内容在 references 里 哪些动作要调 scripts 哪些阶段会有 Hook
也就是说,Skill 不是一上来就让模型看完全部内容,而是:
先触发,再展开主说明,再按需深入
这就是典型的分层加载。
第三步:按需读取
模型进入 Skill 后,并不会机械地把整个目录全读一遍。更常见的情况是按需展开:
缺背景知识了,就读 references 需要固定结构输出了,就读 assets 需要执行确定性动作了,就调 scripts 需要拦截或记录了,就走 Hook
这一步的结果,是把原本一坨 prompt,拆成多个层次的能力组件。你可以把整个运行链路理解成:
索引层 → 主说明层 → 知识层 → 模板层 → 执行层 → 约束层
这就是 Skill 的工程感所在,让模型在合适的时候,拿到合适的东西。
结论
如果把这整套机制抽象一下,你会发现:
Skill 的本质不是模型增强,而是工作流重组
这个认识很关键,因为很多人讨论 Skills 时,还停留在怎么教模型更聪明这个层面。
实际上,Skill 根本拿模型没办法,他就是个工程优化:让工作流从人脑迁移到 Agent 体系里。其目的无非是以下几个,在面对相同问题时:
能不能少从零开始 能不能别每次都乱来 能不能按组织方法做事 …
所以,Skill 不是模型能力的一部分,而是流程的一部分。它的真正价值不是让模型更像一个会聊天的助手而是:让模型更像一个会按 SOP 干活的执行单元
Skill 最终承载的,不是语言,而是方法,还是那句话 Workflow 的迁移。
至此,大家对 Skills 的运行机制应该很清楚了,接下来是 Thariq 文章的核心方法论部分了:
技能分类法
理解完技术结构后,我们回答一个问题: Skill 应该怎么分类?

这里分类的原因就比较上强度了,他的目的不是为了自己玩,而是为了团队层面的运转,也就是只要你想把 Skills 做到组织级,这一步就绕不过去。
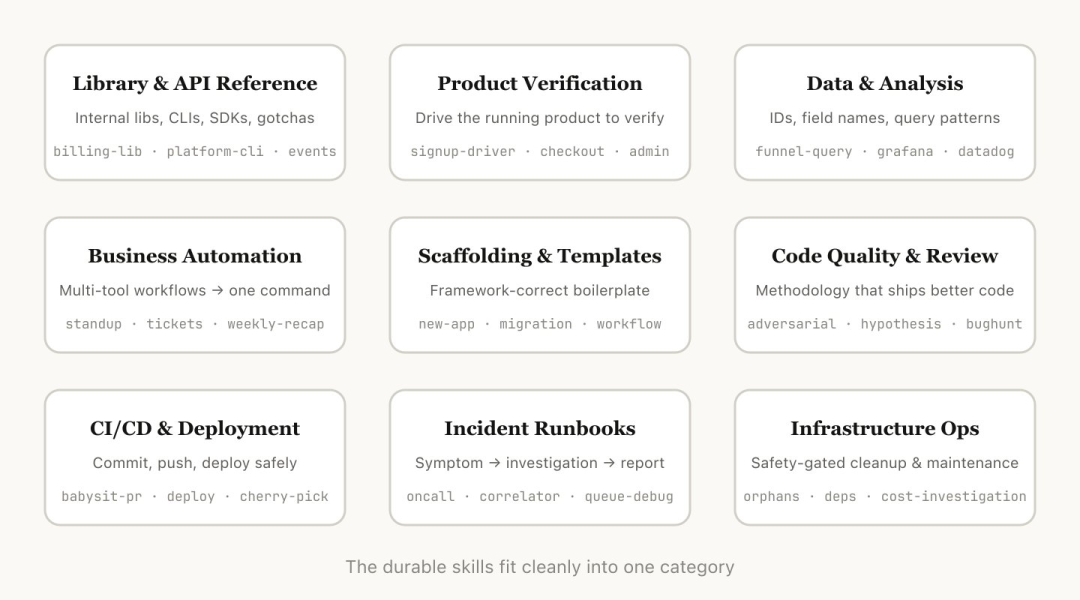
原因也很简单。如果没有分类法,最后所有 Skill 都会堆在一起,然后产生四个后果:
触发混乱 维护混乱 分发混乱 度量混乱
也就是说,没有分类,就没有治理,到最终依旧是工程问题。
Thariq 文章里一个很重要的贡献,就是他不是把 Skill 当灵感集合来聊,而是明确给出了一套技能分类法。
这件事的意义,其实不在于“分了九类”本身,而在于:
他把 Skill 从个人小技巧,推成了可以像产品模块一样管理的能力组合
而 Skills 一旦开始分类,它就不再只是工程师私藏的 prompt,而开始像:
组件库 插件市场 功能矩阵 内部能力目录
另一方面,Skills 分类是很重要的,不同的类型会尤其重要的特性,分类错误也会导致维护困难,比如:
明明应该强调只读,却给了写权限 明明应该做脚本下沉,却还在堆长文案 明明应该强调触发边界,却写得像产品简介 …
无论什么时候分类都是很重要的,分类的结果是回答两个核心问题:
他该扮演什么角色; 这个角色有什么共性,他们的设计方式、治理和分发策略是什么;
接下来就是其九个分类:
1. 参考型
这一类最像“内部知识插件”。它解决的不是执行,而是让模型在某个特定领域里不再瞎猜。
比如:
内部 SDK 的使用规范 某套 API 的调用方式 某个系统的字段口径 某个业务线的规则解释 某个框架的最佳实践
这类 Skill 的重点不在脚本,而在:
知识密度 引用组织 触发边界 坑点介绍
它的价值在于,让模型少犯“看起来会,实际上不会”的错误。
2. 验证型
这一类我认为是整个 Skill 体系里价值非常高的一类。因为它直接涉及质量、返工率和上线风险。比如:
页面验收 埋点核对 接口回归 PR 检查 发布前 smoke test 需求完成度核查
这类 Skill 的特点是:
流程比较明确 验收标准可以部分固定 很适合脚本化 特别适合做模板和断言
它和“参考型”最大的不同在于:
参考型主要在教模型理解,验证型已经开始要求模型出证据
所以这类 Skill 往往最值得打磨,也最容易形成明显 ROI。
3. 数据获取、分析型
这一类 Skill 主要用于:
拉数据 清洗数据 聚合数据 输出分析结论
比如:
拉取核心指标并生成日报 对比多个渠道表现 提取用户反馈并做归类 汇总日志并做异常摘要 读取工单数据做问题聚类
这一类 Skill 的关键不在 AI 会不会分析,而在:
数据源接得稳不稳 口径说明清不清 输出模板固不固定 历史记录能不能复用
所以它往往会同时依赖:
references scripts assets 有时还要持久化状态
这类 Skill 一旦成熟,通常最容易被业务团队喜欢,因为它最接近真的能省人。
4. 团队/业务 流程型
这一类就是我之前常说的,最接近 SOP 包的部分。
它不是单纯为某个工具服务,而是直接承载一个团队或组织的固定流程。比如:
周会前信息收集 需求评审准备 发版前检查 客诉处理 SOP 值班交接流程 周报/复盘汇总
这一类 Skill 的重点不在单点能力,而在,流程迁移,。也就是说,它最像是:
把原本靠人脑记住、靠团队传承的做事方式,迁移成 Agent 可调用的工作流
它的组织价值非常高,因为它承载的已经不只是效率,而是:
流程一致性 组织经验沉淀 新人手册 跨团队协作标准化
5. 模板/脚手架型
这一类 Skill 最像生产工具。比如:
初始化项目结构 生成标准目录 生成 PR 模板 生成需求文档骨架 生成测试用例框架 生成报告初稿
这一类 Skill 的特点是:
输出结构很重要 模板资源很重要 scripts 和 assets 往往比 references 更重要
它的价值在于,减少重复劳动,让组织输出更标准。
6. 代码质量/评审型
这一类主要服务于研发体系。比如:
检查 PR 是否符合规范 审查安全风险 校验测试覆盖 检查依赖升级是否合理 检查是否违反某些内部约定
这一类 Skill 往往需要很强的边界意识,因为它看起来像“审查意见生成器”,但真正有价值的是:
组织特异性的评审标准 常见翻车点 项目历史坑 必须检查但容易漏的细项
它的产出不只是评论,而是把资深工程师的审查经验沉淀下来。
PS:其实从这里也可以看出这个分类法也有不科学的地方,因为有特别针对研发的,那要不要特别针对HR和财务的呢?
7. 部署/CI/运行保障型
这一类 Skill 已经开始靠近高风险区域了。比如:
上线前检查 发布说明生成 回滚流程引导 环境验证 CI 结果总结 分支与依赖状态检查
这类 Skill 往往会碰到:
shell 部署脚本 环境状态 外部系统
所以它的关键已经不只是“会不会写”,而是:
权限怎么控 自动触发要不要禁掉 有没有确认机制 有没有 Hook 约束
这就是组织级 Skill 和个人玩具 Skill 的根本差别之一。
8. Runbook 型
这一类特别有代表性。比如:
某类线上故障排查 某类报警处理 某类数据库异常响应 某类服务不可用的调查路径
这类 Skill 的本质,就是传统运维文档、事故 runbook、经验 SOP 的 Agent 化。
它最适合体现 Skill 的全部价值:
references 承载背景 scripts 承载检查动作 assets 承载输出模板 hooks 承载风险控制 data 承载历史状态
这一类 Skill,也是Workflow 迁移的最好样本。
9. 基础设施/环境运维型
这一类 Skill 最接近高权限执行系统。比如:
基础资源检查 环境配置修复 集群巡检 日志与监控联动分析 资源清理与回收
这类 Skill 的组织价值很高,但风险也最高。所以它在治理上和前面那些类型完全不一样:
更适合手动触发 更适合最小权限 更适合强审计 更适合强 Hook 防护 更适合做成受控分发,而不是开放发现
分类是为了治理
分类当然不是为了好看,他的价值是为了告诉大家:不同类型的 Skill,天然应该走不同的设计路线。比如:
参考型 Skill,更重 references 和 gotchas 验证型 Skill,更重断言、脚本和证据 流程型 Skill,更重步骤编排和模板 Runbook 型 Skill,更重可观测性和风险控制 高风险运维型 Skill,更重权限和人工确认
所以分类的本质,不是知识管理,而是工程治理前提。如果你不先把 Skill 分出来,后面你几乎没法做这几件事:
统一模板 设置准入门槛 分配 owner 设计测试方式 设计权限边界 设计分发渠道 设计度量体系
换句话说,分类法决定了组织级 Skills 落地的效率,没有分类很容易一团糟。
设计原则
这里进入实操技巧分享环节,很多人写 Skill,最容易犯的错,就是总想把背景知识写全、把流程写满,这看起来很完整,实际上价值不高。
因为 Skill 不是写给人复习知识用的,而是写给模型在执行任务时调用的。所以真正有价值的内容,不是常识,而是:
模型默认会容易错的地方 组织内部特有的规则 过去反复翻车的坑 哪些情况不能照常规理解
换句话说:
不要写“大家都知道的”,只写“模型不知道但又很关键的”。
这里最值得沉淀的,就是 Gotchas。这个所谓 Gotchas 在原文里面出现了很多次,很多同学看不懂,大白话就是:
易错点 反常识规则 历史翻车案例 默认直觉会误判的地方
其实核心就一句话:纠正模型最容易做错的地方。
其次就是第二原则了:能下沉成脚本的,不要继续用文字硬写!
模型擅长理解、规划、解释、串联。但重复执行、精确校验、固定格式转换、稳定抓取数据,这些事天然更适合交给脚本。总体建议是:
模型负责理解和调度 脚本负责确定性执行 模板负责稳定输出 references 负责按需补知识
PS:这里提到的脚本大家也不用紧张,我们后面有大量的 AI Coding 文章,帮助大家写脚本
分发与治理
我们在过往使用 Tools(Function Calling) 的时候最烦的就是:Tools 多了不好维护,而且加载起来还容易出错,Skills 本身是用来“包裹”一堆 Tools 的,但现在却已经出现了 Skills 过多而导致的系统失控问题…
这里尤其明显的就是个人和团队,个人玩 Skill,关注的是好不好用;团队上 Skill,关注是:
会不会乱触发 会不会互相冲突 会不会增加上下文负担 会不会越权 会不会越来越难维护
所以 Skill 一旦做大,核心问题就不再是“怎么写”,而是“怎么管”。这也是为什么我们很强调分发层级这个概念。
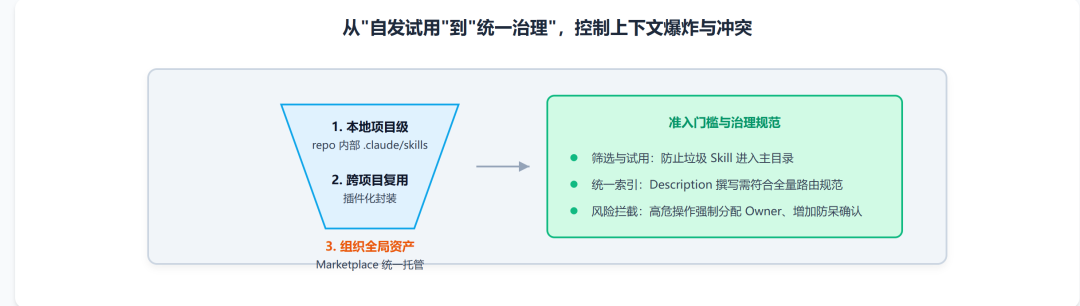
小团队阶段,Skill 放在 repo 里的 .claude/skills 就够了;但当 Skill 数量增加、团队扩大后,就需要往插件、Marketplace、企业统一托管这些方式演进。原因很简单:
不是所有 Skill,都值得默认进入上下文。
每多一个 Skill,就多一份触发和上下文成本。所以组织级落地一定会走向两件事:
第一,分层分发。
项目专属的,放项目里;跨项目复用的,做插件;组织通用的,再进入统一目录。
第二,建立准入门槛。
不是谁写了一个 Skill 都直接开放给所有人用,而是要经过试用、筛选、评审,再决定是否进入主目录。
说白了,Skill 到了组织级,他就已经变成了:一种要被被治理、被维护的内部能力资产。
当然,如果是个人用,就随意了,一般来说都做不了多大…
在过往经验里,有一类尤其要单独强调,就是高风险 Skill。
比如部署、删资源、改配置、生产运维这类能力,不能按普通 Skill 来处理。这个要注意,至少得知道是谁触发的,怎么触发的,出了问题怎么追责。
可观测性
只要是 AI 项目,就一定离不开可观测性,很多团队现在做 Skill,都停留在一种很原始的状态:
写出来了 大家觉得还行 就继续放着
但 Skill 一旦没有度量,就会出现三个问题:
你不知道它有没有被用 你不知道它是不是乱触发 你不知道它到底有没有创造收益
怎么办呢,原文给了一个非常实用的思路:用 Hook,尤其是 PreToolUse 这一类埋点方式,去记录 Skill 调用情况。
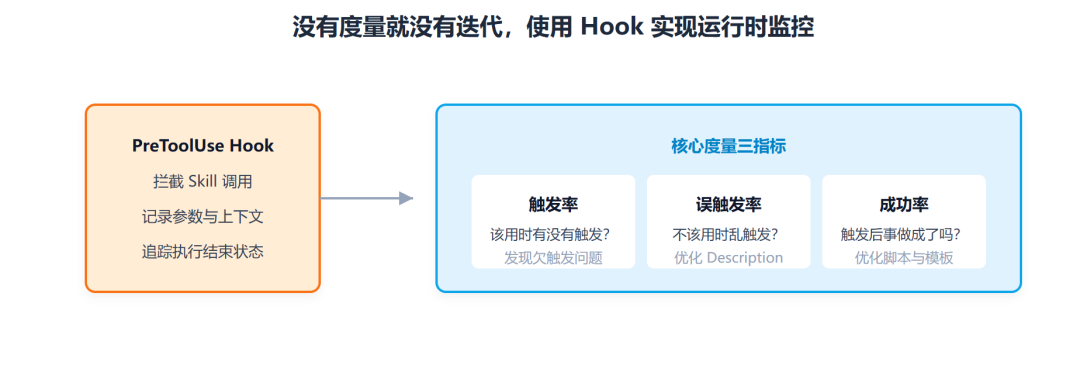
于是就可以看到:
哪些 Skill 被频繁调用 哪些 Skill 几乎没人用 哪些 Skill 触发后经常失败 哪些 Skill 可能存在过触发
这个东西从技术层面并不难,只不过在工程层面是需要设计的,如果只保留最核心的指标,后面写三个就够了:
触发率。该触发的时候,有没有触发到 误触发率。不该触发的时候,有没有乱触发 成功率。触发之后,最终有没有真的把事做成
有了这三个指标,Skill 才真正具备迭代基础。否则,所谓优化,大多只是拍脑袋。
最后,从团队视角看,Skill 的完整闭环其实是:
分类 → 设计 → 分发 → 度量 → 迭代
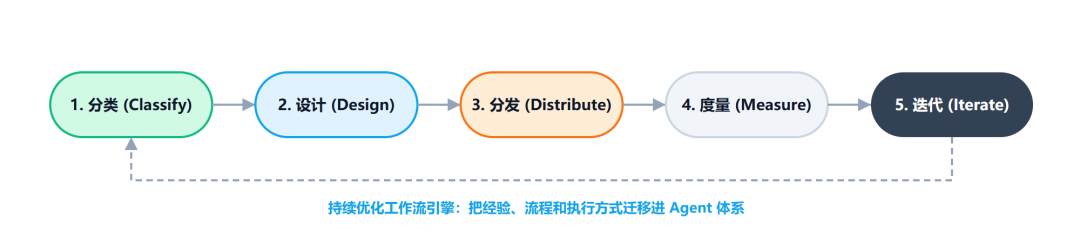
前面几步解决的是能不能被做出来,最后这一步解决的是:它能不能持续活着,并不断变好。
结语
首先十分感谢 Thariq 大佬这篇关于 Skills 的文章,他让我本身关于 Skills 知识会变得更系统一些,主要是分类部分十分有借鉴性,其他包括可观测性,其实也是我们一直在强调、在做的,他的文章是再次确认了我们做法的正确性。
如果把这篇文章再压成一句话,其实就是:
Skill 不是更长的提示词,而是一种承载组织工作流的新型工程单元
它里面装的,不只是说明文字,还包括:
知识 模板 脚本 约束 度量方式
所以 Skill 其实是一套优良的工程解法,他对模型毫无影响,而是:把经验、流程和执行方式,迁移进 Agent 体系的方法。
这也是为什么我前面一直说,Agent 真正的核心,不只是记忆,而是 Skills。
记忆解决的是知道什么,聊起来不傻。而 Skills 解决的是:遇到事之后,按什么方法去做,并且尽量每次都做对。
好了,篇幅很长了,就不赘述了,希望对大家有用吧..
