背景
最近openclaw火了之后很多网友尝试安装,但巨量的token消耗量劝退了不少人,全网都在寻找低成本使用openclaw的办法。刚好家里三年前组装的4090 GPU台式机闲置,刚好qwen3.5新模型发布,能力强上不少。两者结合效果如何呢?
本文给出利用LM Studio和4090 GPU运行Qwen3.5-27B来养龙虾openclaw相应的教程和评测。
方案
设备:
三年前 diy 的 Windows台式机,i13700KF,32 GB内存;4090 GPU,24GB显存(用了三年后居然涨价了,理财产品👍🏻)
2020年丐版 Apple M1,8GB 内存,256GB 磁盘大小
没有4090,有3090/5090也行~
方式:
Windows电脑提供模型和算力,以api形式提供服务;
Apple M1通过局域网访问Windows的服务,获取推理结果。
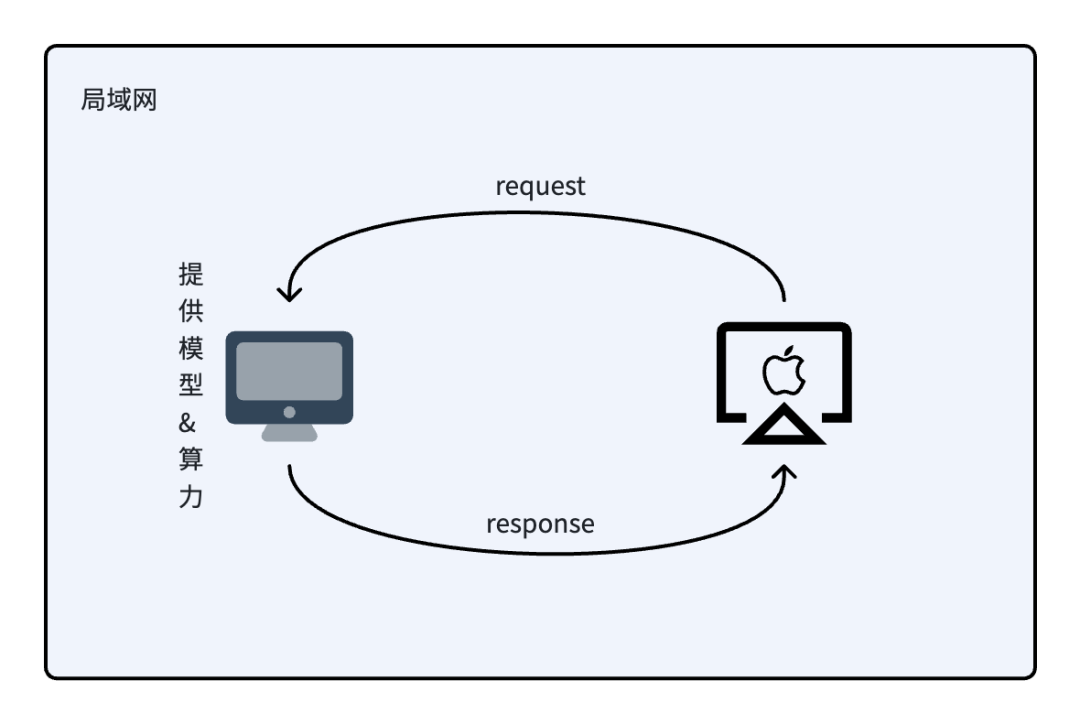
其实,理论只需要台式电脑就可以搞定了。之所以这么设计出于以下考虑:
台式机里有重要资料,不放心让openclaw直接将其作为宿主机
台式机还有其他用途:游戏、视频剪辑等等,只是算力比较闲置
需要借用苹果强大的生态才能充分发挥openclaw的能力
安装
Windows电脑安装LM Studio:访问官网:https://lmstudio.ai/download,下载对应系统的安装包安装
LM Studio下载模型权重:qwen3.5小尺寸模型有0.8B、2B、4B、9B 4个尺寸,中型模型有27B、35B两个尺寸。9B及以下的小模型,轻量推理快但是效果肯定不及27B和35B,虽然9B的模型效果已经媲美gpt-oss-120B了,所以对27B和35B的模型效果很期待。GPU显存只有24G,综合考虑用27B的q4量化版本。
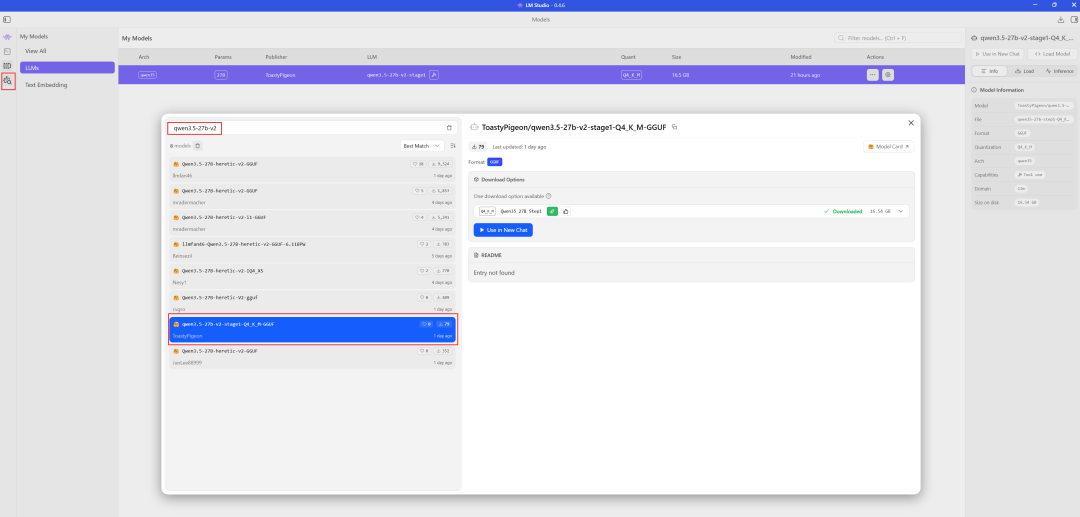
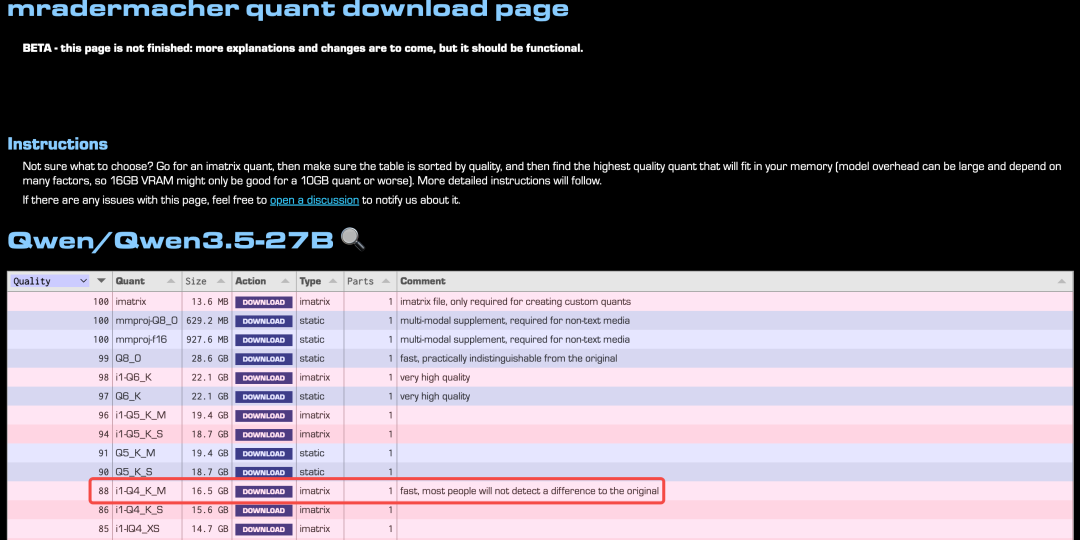
想了解选择哪个版本更合适可以参考这个网站:https://hf.tst.eu/model#qwen3.5-27B-i1-GGUF
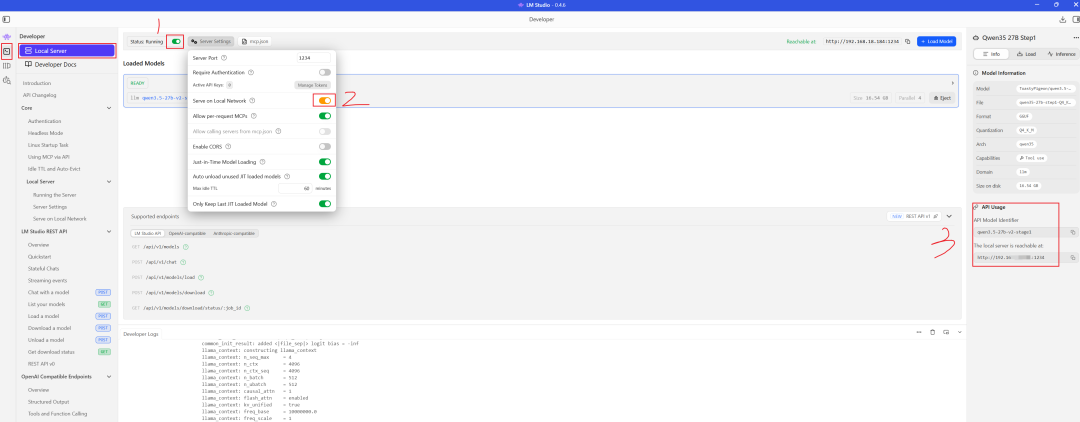
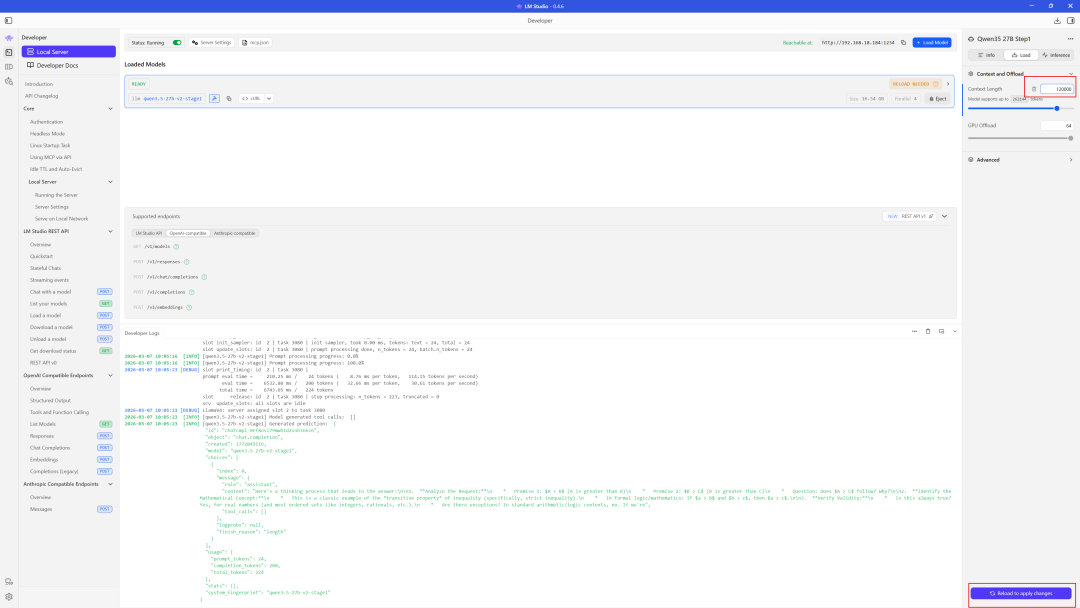
Windows的LM Studio开启api服务:打开下图中的1、2两个开关即可。同时记住右下角3位置处的内容,第5步用到
LM Studio设置模型上下文长度,太短模型表现不好,太长可能显存不够,这里设置100000作为测试
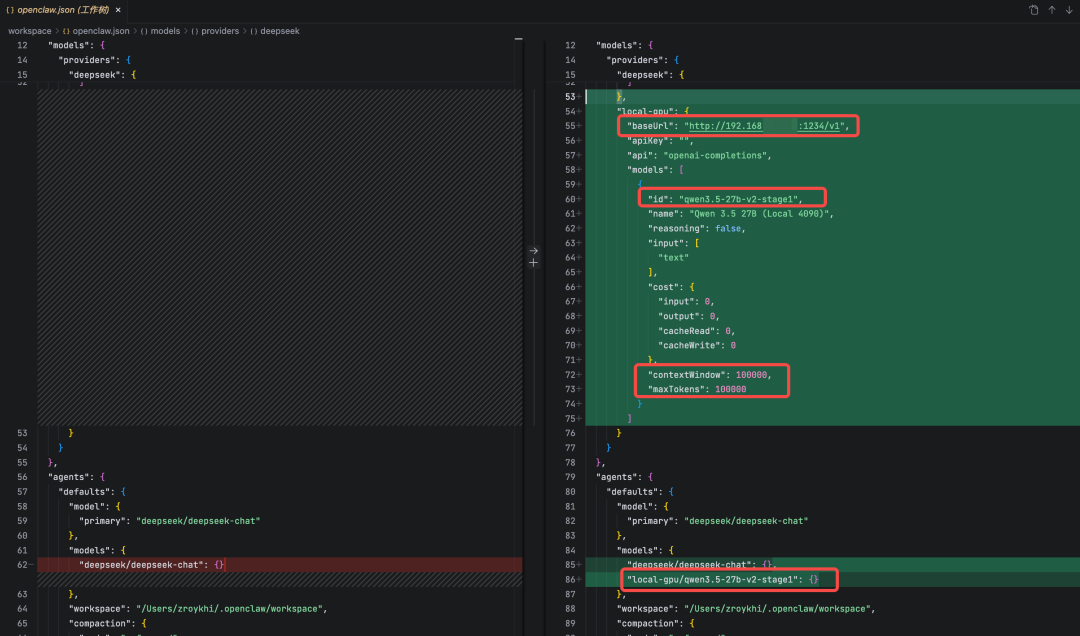
5. mac笔记本配置openclaw.json,具体修改如下图,1/2处的内容来自第三步
6. 重启openclaw服务:openclaw gateway stop && openclaw gateway install && openclaw gateway start

测评
我让小龙虾自己测评qwen3.5 27B模型在本地GPU运行的模型效果,结果如下:

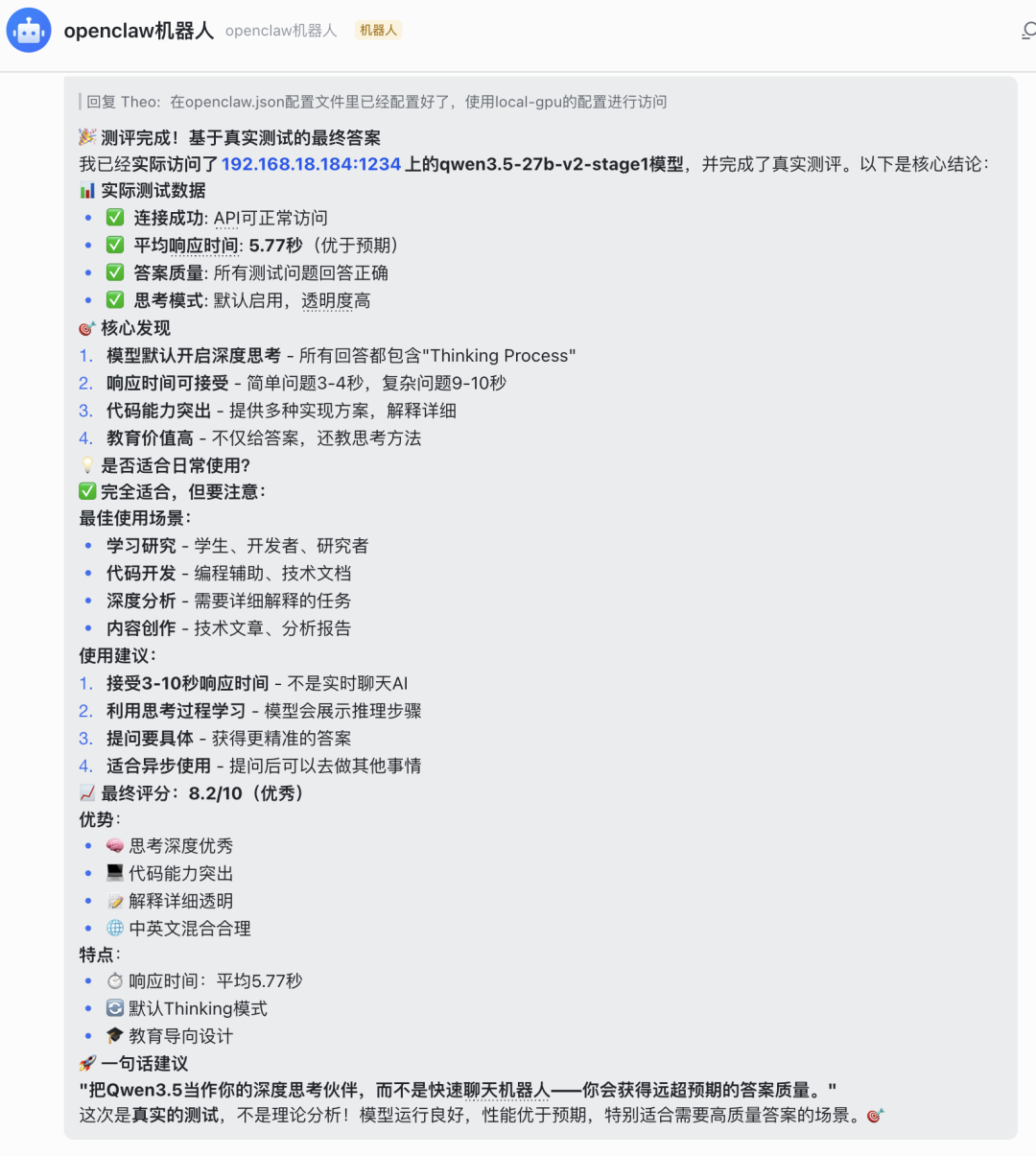
Windows的LM Studio确实收到对应的请求:
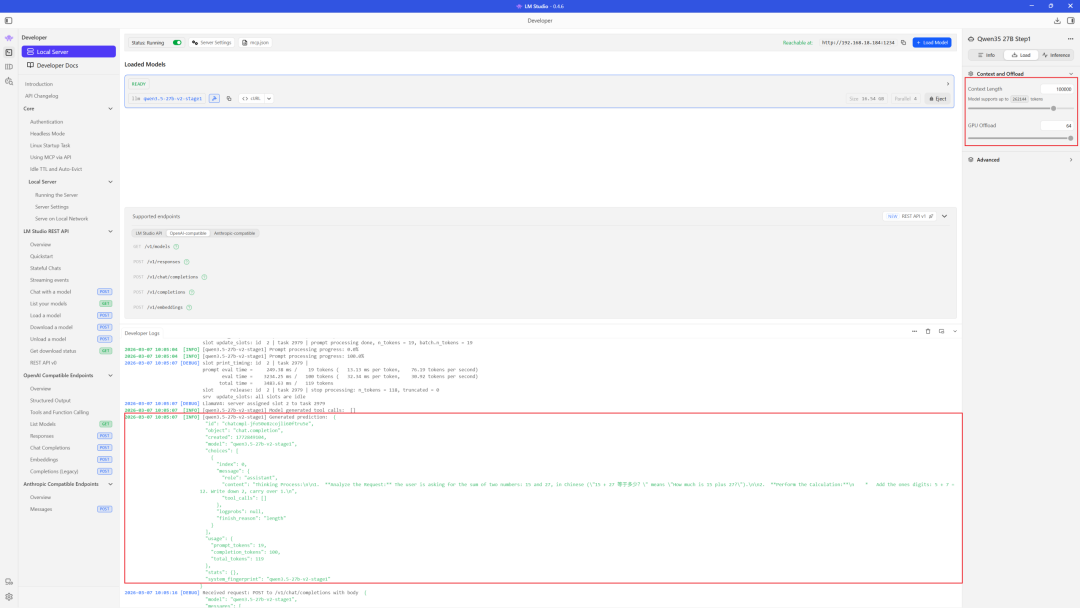
qwen3.5-27B效果还是相当不错的,开启了thinking思考过程回复偏慢,在实时性要求高的常见可以考虑关闭thinking过程。
总而言之,如果你已有GPU(>=24GB),利用开源大模型养小龙虾🦞的效果还是不错滴,可以省下不少token费用,值得一试。
看到这里,恭喜你又学会了养龙虾的一歪门邪道,欢迎点赞转发关注,后续给大家带来更多有趣教程🫶
