大家好,我是青澈君,一个喜欢捣鼓openclaw的80后,顺便学学Vibe Coding,也在坚持写日记。
我的 OpenClaw 上跑着 16 个 agent,靠一套三层 memory 文件体系来维持记忆。用了将近两个月,整体能用——跨会话的决策不会丢,新会话开起来能接上之前的工作。
之前也分享了我在用的三层记忆系统openclaw记忆越塞越多,我花一晚上给龙虾们做了大瘦身
但有一个问题一直悬着:对话内的记忆。
小开(dev agent)写代码的时候,经常一个会话聊 100 多轮。聊到后半段,偶尔会出现和前面讨论过的约定不一致的情况。不是每次都这样,但发生的时候挺烦——你得重新说一遍,或者翻聊天记录把上下文补回去。
这不是 agent 的问题,是上下文窗口的物理限制。
先说清楚上下文窗口这件事
所有大模型处理对话,底层是把历史消息拼成一段长文本送去推理。这段文本有大小上限,叫”上下文窗口”。Claude 大概 20 万 token,听起来宽裕,但工程类对话每轮都在讨论代码和错误日志,100 轮左右就能撑到边界。
超出部分怎么办?OpenClaw 的默认策略是砍掉最旧的消息。直接砍,没有备份。这就是对话内遗忘的根源。
我的三层 memory 体系解决的是跨会话记忆(下次开新对话还记得),但对话内这个窗口限制,它绕不过去。所以当我发现有个插件能从底层解决这个问题的时候,觉得值得试一下。
以前的应对:三层 memory 文件
我很早就搭了一套外挂记忆系统,基于 markdown 文件,16 个 agent 共享读写,分三层:
MEMORY.md(索引层): ≤ 2KB,每次新会话自动注入。只放 topic 文件指针和红线规则。相当于一张目录卡片。
topic 文件(知识层): 按项目一个文件,≤ 3KB,存提炼后的技术决策和架构方案。跨日累积更新,过时信息直接替换。
daily 日记(日志层): 按天一个文件,记当天操作的精炼摘要。
工作流:新会话开始 → 读 MEMORY.md + 今天/昨天 daily → 按需读 topic → 干活。关键节点手动 /save 落盘。
这套系统管住了”跨会话”的遗忘——下次开新对话,助理还记得上次的决策。但”对话内”的遗忘管不了。上下文窗口满了就砍,文件体系绕不过去。
而且这套体系自己也在出问题。我后来拉了一次数据:47 天 47 个 daily 文件,39 个超出 2KB 限制,最胖的膨胀到 14KB——规定上限的 7 倍。更离谱的是,memory_search 因为本地依赖缺失,其实一直是坏的。助理号称”先查 memory 再回答”,实际上搜不了,全靠开会话时硬读几个文件碰运气。
一套用来对抗遗忘的系统,自己先乱了。
LCM 是什么
然后我发现了「LCM」——Lossless Context Management(无损上下文管理),「Martian Engineering」做成了「OpenClaw」插件:https://github.com/Martian-Engineering/lossless-claw 。
核心机制用一个比方讲清楚:
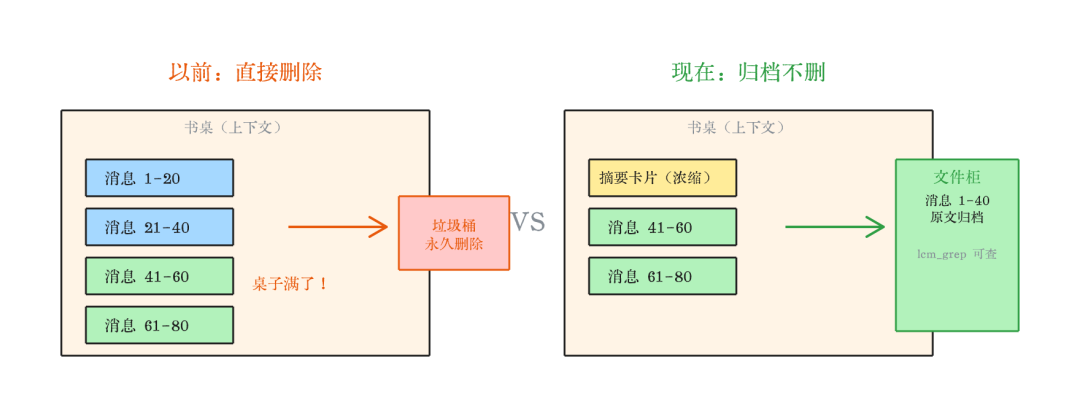
你有一张书桌(上下文窗口),一直往上堆笔记(对话消息)。以前桌子满了,把最底下的笔记撕掉扔垃圾桶。LCM 的做法是:把最底下一摞笔记收起来,写一张目录卡片概括要点放回桌上,笔记本身归档到旁边的柜子(SQLite 数据库)里。目录卡片多了,再合并成更高层的卡片。层层嵌套,越早的越”浓缩”,但从来不删。
桌子永远不会溢出,柜子里的东西随时能翻。
怎么装
一条命令:
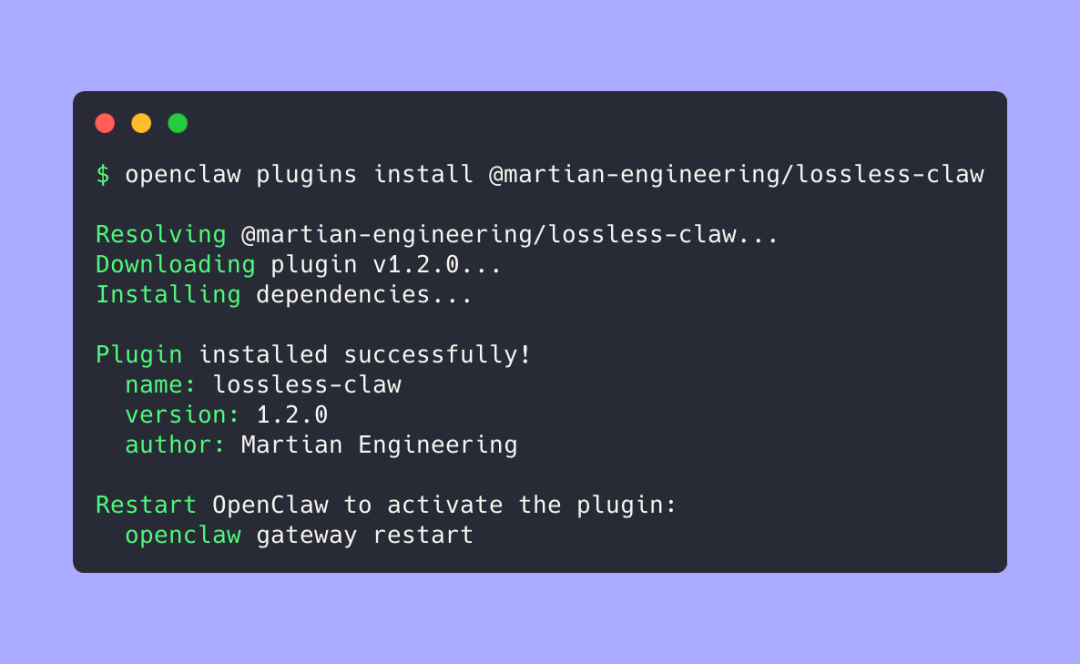
1 分钟装完,重启即生效 。两个关键默认值:上下文满 75% 自动触发压缩,最近 32 条消息保持原文。摘要模型用 Sonnet,便宜够用。数据存本机 SQLite,不走云端。
装完之后,发生了什么
我直接问小皮(主助理),它给了一个清楚的对比:
以前聊 50 轮,上下文快满了,OpenClaw 直接砍掉最早的 30 轮,真没了。现在 LCM 把最早的 20 轮压成摘要,塞回上下文顶部,原文存进数据库。你要翻旧账,用 lcm_grep 搜数据库找原文。永远不丢消息。
那还需要 /save 吗?
还需要,但场景变了。LCM 管”同一对话内不忘”,你一 /new 开新会话,LCM 的摘要不会自动注入。新会话靠什么恢复?还是靠 memory 文件。
分工:LCM → 对话内记忆(自动)。Memory 文件 → 跨会话记忆(手动 /save)。
变化是 /save 从”焦虑式落盘”变成了”从容式落盘”——过程细节 LCM 自动留底,/save 只挑跨会话有价值的结论。
实际感受到的变化:长对话不再突然失忆,/save 压力变小,新会话能用 lcm_grep 翻旧账,16 个助理全覆盖。
LCM 保证聊着不忘,Memory 保证下次还记得。 两个加起来,才算把记忆配齐了。
装完不是终点:配套改造
插件装好只是第一步。底层机制变了,上层的规则和流程也得跟着调。我让小皮做了一次全面体检,发现六个问题,逐一修了:
修复 memory_search。 搜索引擎从坏掉的本地模型切到远程 Gemini embedding,一行配置,memory 文件终于能正常检索了。
daily 日记减负。 上限从 2KB 降到 1KB,从”操作日志”变成”决策清单”,只记结论。历史 41 个超限文件(276KB)全部归档到 _archive。
清理冗余快照。 memory 目录下 10 个会话快照文件,LCM 已替代这个功能,全部归档。
上下文管理规则松绑。 原来”超 60% 就赶紧落盘 + 建议重开”是防御策略,现在 LCM 在 75% 自动处理,取消过度防御的规则,不再频繁打断。
落盘纪律精简。 新增核心原则:”LCM 有的不重复写”。调试过程、中间方案对比全部交给 LCM,/save 只写决策和状态变更。
会话恢复加兜底。 开场流程新增一步:读完 memory 文件后如果信息不够,用 lcm_grep 搜近期对话补充。偶尔忘了落盘也不至于断档。
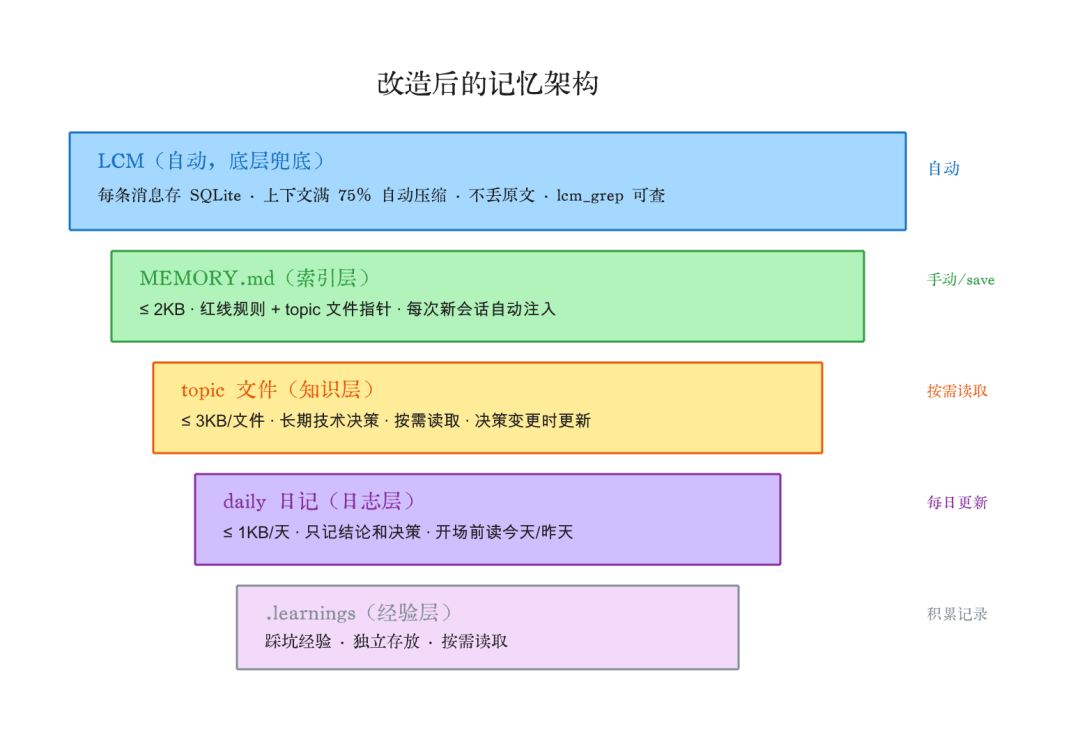
改造后的记忆架构:
- LCM(自动): 每条消息存 SQLite,上下文满 75% 自动压缩,不丢原文
- MEMORY.md(≤ 2KB): 索引 + 红线规则,每次新会话自动注入
- topic 文件(≤ 3KB): 长期知识沉淀,决策变更时才更新
- daily 日记(≤ 1KB): 每天的决策清单,只记结论
- .learnings: 踩坑经验,独立存放
从”怕丢所以多记”变成了”LCM 兜底所以只记精华”。架构没变,每层变薄了。
关于文件大小限制
有了 LCM 之后,memory 文件的大小限制还有必要吗?
有,但理由变了。 以前限大小是怕丢——文件越大,吃上下文越多,越早触发压缩丢消息。现在限大小是为了效率——LCM 解决了”丢”的问题,但上下文窗口大小没变。每次新会话要加载这些文件,文件越瘦,留给正事的空间越多。
1KB 的 daily 和 14KB 的 daily,对模型来说就是能多聊十几轮正事还是不能的区别。LCM 不增加窗口大小,只是让压缩不再丢消息。窗口还是寸土寸金。
局限
摘要质量取决于模型。 我用 Sonnet 没问题,但用太便宜的模型可能丢要点。原文在数据库里不会真丢,但 agent 需要主动展开才能找回。
跨 agent 记忆共享仍靠 memory 文件。 LCM 按会话存储,小开和小文的记录是独立的。跨 agent 信息同步还是得手动落盘或通过主助理协调。
数据库会持续增长。 每条消息都存,长期下来需要关注 lcm.db 的大小,可能半年后需要归档策略。
最后
记忆是 AI 助理的基础设施,基础设施出问题,上面所有能力都打折扣。我花了将近两个月搭 memory 文件体系来对抗遗忘,最后发现人工维护的记忆系统自己也会乱。
LCM 从底层解决了”对话内遗忘”。装上之后不只是多了个插件,而是整个记忆体系的运转逻辑变了:从防御式的”赶紧记”变成了从容的”只记精华”。
但 LCM 不是万能的,它管对话内,memory 文件管跨会话,缺一不可。真正让记忆系统好用的,不是某一个工具,而是搞清楚每一层该存什么、不该存什么。
如果你也在跑 OpenClaw,尤其是多 agent 场景,可以试试 lossless-claw。一条命令,3 分钟。装完记得顺便体检一下你的记忆体系——可能有些问题,借这个机会一起修了。
你的 agent 聊到第几轮开始”失忆”?欢迎留言交流。

